

First created at LinkedIn to empower business and user-facing problems, Pinot was then donated to Apache in 2019. Apache Pinot, an open-source, real-time, column-oriented, distributed Online Analytical Processing (OLAP) datastore, written in Java. Pinot is designed to deliver low-latency, real-time analytics. Apache Pinot is built to horizontally scale when needed to help scale larger data sets and higher query rates.
Apache Pinot can ingest data from streaming sources like Apache Kafka or AWS Kinesis, and batch data sources like AWS S3, Google Cloud Storage, Hadoop Distributed File System (HDFS), and Azure Data Lake. Apache Pinot is being used by brands like Uber and Microsoft for production purposes.
Read: What is Apache Druid Architecture?
Having a columnar store at the core with pre-aggregation techniques and smart indexing, Apache Pinot offers low latency. Pinot is not only perfect for user-facing real-time analysis but also other analytical use cases, such as anomaly detection, internal dashboards, and ad-hoc data exploration.
Basic Apache Pinot Concepts
Apache pinot has been developed to offer low latency queries on large datasets. To achieve this, data in Apache Pinot is stored in a columnar format and adds extra indices for fast filtration, group by, and aggregation.
Raw data in Pinot is broken down into small shards where each shard is transformed into a unit called a segment. One or more segments are combined to form a table (logical container), where Apache Pinot performs queries using SQL/PQL.
A Pinot cluster has multiple distributed system components (i.e. Controller, Server, Broker, and Minion) that are valuable to understand for debugging and error or monitoring system usage with a cluster deployment.
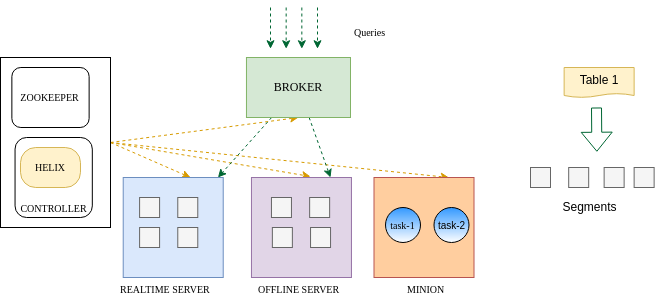
In the above diagram, Pinot Controller is the core orchestrator that handles routing and consistency in the cluster of Apache Pinot.
A Pinot broker receives queries from clients and routes them to one or more Pinot servers before returning a converged response.
Pinot servers are independently horizontally scaling containers that host scheduled shards (segments) and allocate them across multiple nodes and route them on a tenant assignment.
Apache Pinot minion is optional but can be used to run background tasks. Minion provides a solution for the security of private data that complies with GDPR while optimizing Pinot segments. Apache Pinot minion also helps in building additional indices that offer performance even in the data deletion possibilities presence.
Apache Pinot Architecture & Its Features To Help Businesses
As discussed in the above section, Apache Pinot has multiple distributed components: Controller, Broker, Server, and Minions. Apache Pinot uses Apache Helix for managing clusters. Helix in the architecture of Apache Pinot is implemented as an agent within different components and uses Apache Zookeeper to maintain and coordinate the state and health of the overall cluster.
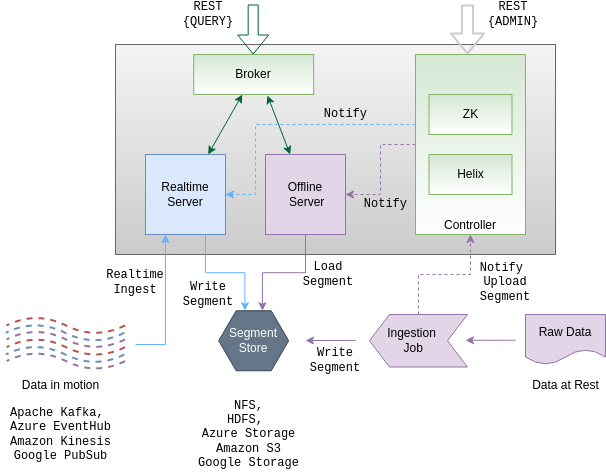
The above image describes the workflow of the Apache Pinot architecture. To better understand this image, refer to the below points:
-
A logical table in the Apache Pinot is formed either as offline or real-time physical tables. Both real-time and offline tables have different options for configuring indexes. While real-time tables have a smaller retention period and scales query performance according to the ingestion rate, it uses stream data sources like Apache Kafka, Amazon Kinesis. Offline tables have larger retention and scales performance according to the stored data size, hence, it uses virtual machines with larger storage capacity like Amazon S3 and HDFS.
-
In batch mode, Pinot ingests data through an ingestion job that transforms raw data sources into segments (a representation of a chunk of table data). The ingestion job then stores the segments into the deep store (cluster’s segment store) and informs the controller. After processing the information, the Helix agent on the controller updates the ideal state configuration in Zookeeper. Then the offline server will be notified for new segment availability then the segments are downloaded into the deep store and finally added into the list of query segments (segment-to-server routing table).
-
For real-time data flow, a controller creates a new entry in Zookeeper for the consuming segments. Then the Helix agent notices and notifies about the new segment to the real-time server which in return starts ingesting data from the streaming source. The broker handles the changes, detects new segments and adds them to the list of query segments (segment-to-server routing table).
-
Brokers receive the queries and check the requests against the segment to the server routing table while dividing the requests between offline and real-time servers. The request is then filtered and aggregated by the two tables and returns the result to the broker. And the broker returns the collected information to the client as a result.
Features of Apache Pinot
The features that empower Apache Pinot to provide real-time analytics with low latency are as follows:
-
Pluggable indexing: Apache Pinot supports multiple indexing techniques like Forward Index, Star-tree Index, Inverted Index, Bloom Filter, Text Index, Range Index, etc.
-
Stream and Batch Data Ingest: Apache Pinot allows near real-time data ingestions from batch and stream ingestions from Hadoop.
-
Query Optimization: Apache Pinot allows optimization of query depending upon the segment and query metadata.
-
Column-Oriented: Apache Pinot stores a large amount of data tables by column instead of row and offers compression schemes like Fixed Bit Length, Run Length, etc.
-
Multi-valued Fields: Apache Pinot enables you to query fields as comma-separated-values as it supports multiple values in a field.
-
SQL like Query Interface: Apache Pinot’s SQL-like query language (PQL) allows aggregation, selection, filtering, order by, group by, queries on data.
Takeaway
Apache Pinot, which originated at LinkedIn, powers more than 50 user-facing applications like Ad Analytics, Who Viewed my Profile, Talent Analytics, and more. Pinot serves as the backend for monitoring and visualizing more than 10,000 business metrics. As Apache Pinot runs on 1000+ nodes, it serves 100,000+ queries while ingesting 1.5 million+ events per second.
Read: How Docker Container Works?
However, one thing to remember is that Apache Pinot is not a replacement for a database and cannot be a truth store source as it cannot mutate data. However, it is a perfect fit for fast analytics and queries containing lots of dimensions and metrics. Companies that are using Apache Pinot include LinkedIn, Uber, Factual, Microsoft, and Weibo.
If you too want Apache Pinot in your business application for low latency and quick OLAP queries, hire developers who have gained experience working with this technology.