
Quick Summary
-
Choosing between SOA and microservices is a decision about scope, resilience, release cadence, and operating cost. SOA excels at enterprise reuse and consistent governance across departments, which keeps integration tidy but can slow change if central layers bottleneck.
-
Microservices favor independently deployable services aligned to product domains, enabling faster iteration and granular scaling with a higher platform burden. Industry research shows outages remain expensive, so reliability, observability, and a realistic migration plan are critical regardless of approach.
-
The best teams often blend both: SOA patterns for integration, microservices for change-heavy domains. This guide gives you a practical decision framework and an implementation roadmap that reduces regret.
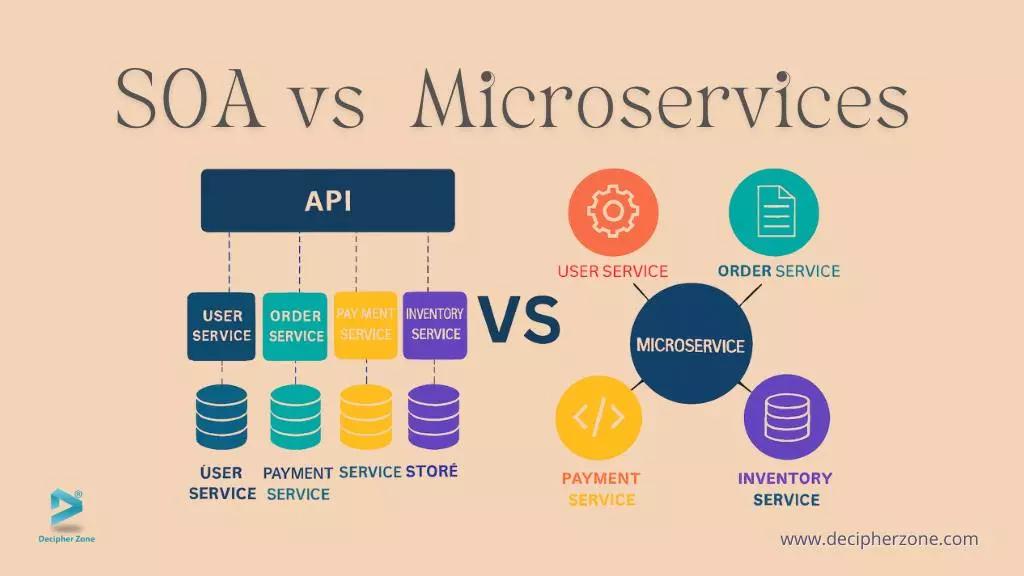
What is SOA
Service Oriented Architecture organizes capabilities as reusable services that many applications can consume across an enterprise. SOA typically emphasizes central mediation via an ESB or API management layer, stronger interface contracts, and shared data models, which improves consistency at scale.
This enterprise scope makes SOA a natural fit for integrating legacy ERP, HR, finance, and government systems while enforcing policies. The tradeoff is that central layers can turn into change bottlenecks without modern resiliency patterns.
Treat SOA as an integration backbone, not a monolith, and pair it with lightweight gateways and consumer-driven contracts. IBM’s guidance frames the key idea: SOA is enterprise scope first.
In practice
-
Enterprise scope and reuse reduce duplication and integration sprawl.
-
Standard contracts help departments collaborate safely.
-
API gateways shield downstream systems and apply policies.
-
Central layers need circuit breakers and rate limits to avoid bottlenecks.
Read: software development
What are Microservices
Microservices structure an application as small, autonomous services that can be built, deployed, and scaled independently. Teams align services to bounded contexts, adopt containers and orchestration, and rely on automation to ship changes frequently with a small blast radius.
This model favors product agility, selective autoscaling, and fault isolation when one service fails. The platform burden is higher, so teams need CI/CD, observability, security automation, and a consistent “golden path.”
Adoption trends in cloud native ecosystems show why the microservices path is common for fast-moving products. The catch is to avoid premature splitting that creates a distributed monolith.
In practice
-
Independent deployability enables rapid change and rollback.
-
Polyglot stacks are possible with clear contracts and guardrails.
-
Event-driven integration reduces chatty RPC coupling.
-
Platform engineering and SRE maturity are essential.
Deep dive: What are Microservices?
Key Differences Between SOA and Microservices
The most important distinction is scope. SOA aims at enterprise-wide reuse and integration, while microservices focus on an application or product domain. SOA often uses shared services behind a gateway or ESB, whereas microservices prefer loosely coupled services that collaborate through APIs and events.

Deployability differs as well, with SOA more commonly released in coordinated windows and microservices released per service. Team structure follows suit, from centralized governance to autonomous squads.
The ops profile is simpler for SOA and heavier for microservices, which require solid observability and security foundations. AWS and IBM both highlight scope as the north star for your decision.
| Dimension | SOA | Microservices |
|---|---|---|
| Primary scope | Enterprise integration and reuse | Application or product domain |
| Coupling | Shared services via gateway or ESB | Loosely coupled APIs and events |
| Deployability | Coordinated releases | Independent releases per service |
| Team model | Central governance | Small autonomous squads |
| Tech stack | Often standardized | Polyglot with guardrails |
| Ops burden | Fewer deployables | More services, stronger DevOps/SRE |
When to Choose SOA
Choose SOA when cross-department reuse, standardized contracts, and predictable release windows matter more than hyperspeed iteration. SOA is compelling where several internal systems must share canonical data models, and where compliance prefers approved stacks and clear approvals.
If an API management layer or ESB already exists, you can capitalize on existing skills and governance. Keep an eye on change hotspots and design for evolution so that you can peel out microservices later.
With observability and circuit breakers in the gateway, SOA remains a stable foundation for integrated enterprises.
Signals SOA is a good starting point
-
Strict consistency across many departments.
-
Coordinated maintenance windows are acceptable.
-
Existing ESB or API management investments.
-
Central team managing standards and contracts.
Benefits and Drawbacks of SOA
SOA accelerates delivery for integration-heavy use cases by reusing shared capabilities and reducing duplication. The standardized stack eases onboarding and simplifies deployments with fewer moving parts. Infrastructure overhead is often lower than a large fleet of microservices.
Drawbacks appear when central dependencies become single points of failure or when big, coordinated releases slow experimentation. Hardware limits on large instances and bandwidth ceilings can also bite. Use gateways, bulkheads, and caching to mitigate these risks while preserving reuse and consistency.
Benefits
-
Faster delivery via reuse in integration-heavy landscapes.
-
Lower infrastructure overhead than many small services.
-
Easier onboarding due to common standards.
-
Predictable releases with simpler runbooks.
Drawbacks
-
Potential bottlenecks in central mediation layers.
-
Coordinated releases can slow change.
-
Harder to adopt best-of-breed stacks across domains.
-
Large instances can hit bandwidth or hardware ceilings.
When to Choose Microservices
Choose microservices when you need near-zero downtime, frequent independent releases, and selective scaling on hot paths. This model works best for product teams that ship features weekly or daily, where regional latency and failover matter.
Start small with clear domain boundaries and a thin slice that exercises the platform end to end. Avoid over-splitting; extract services where change pressure and usage justify the operational overhead.
Plan for a service mesh, tracing, secrets management, and progressive delivery from day one to keep reliability high as services multiply. Amazon Web Services, Inc.
Signals microservices fit better
-
Strict uptime and fast rollback targets.
-
Multiple squads shipping in parallel.
-
Uneven traffic that benefits from granular autoscaling.
-
Platform engineering and SRE are in place.
Explore: Benefits of Microservices Architecture

Benefits and Drawbacks of Microservices
Microservices offer high availability and fault isolation when services fail independently, plus faster iteration through independent deploys and rollbacks. Polyglot freedom lets teams choose the best tool for each job with clear contracts.
Autoscaling directs spend to where demand exists. On the downside, testing and data consistency are harder, and the platform burden rises without strong governance. Migration can take longer, and operational cost can creep without consolidation and templates.
A pragmatic platform approach turns these risks into manageable tradeoffs.
Benefits
-
Fault isolation and rapid rollback keep outages contained.
-
Faster iteration with independent deployments.
-
Polyglot stacks with stable contracts.
-
Cost focus through targeted autoscaling.
Drawbacks
-
Complex testing and consistency across services.
-
Higher observability and security investment.
-
Longer migration without a roadmap.
-
Tool sprawl unless templates and guardrails exist.
Further reading: Ways to Ensure Failure of Microservices
Cost, Time, and Team Composition
Architecture economics are driven by change cost, run cost, and failure cost. Change cost includes engineering time, testing depth, and coordination overhead. Run cost spans compute, storage, network, observability, and security tooling. Failure cost is dominated by downtime, SLO breaches, and incident response.
CNCF surveys show sustained cloud-native adoption but also rising concerns about complexity and documentation, underscoring the value of a strong platform function.
Choose team structures that match the path: centralized integration teams for SOA, cross-functional squads plus platform and SRE for microservices. Track DORA metrics to validate that structure is paying off.
Helpful DZ guides
Reliability, Observability, and Downtime Risk
Downtime is still expensive in 2025, so reliability must be designed in from the start. Siemens estimates the world’s 500 biggest companies lose about 11 percent of revenues to unplanned downtime, roughly 1.4 trillion dollars a year.
New Relic’s recent reporting and press data show many high-impact outages cost around 2 million dollars per hour, and proactive observability can cut that impact significantly. News coverage continues to highlight large losses across sectors, keeping reliability on every board agenda.
Build SLOs for top user journeys, practice progressive delivery with automated rollback, and run game days to validate runbooks. Observability should cover metrics, logs, traces, and synthetics with clear on-call routes.
Reliability building blocks
-
SLOs and error budgets tied to user journeys.
-
Canary and blue-green releases with health-based rollback.
-
Chaos drills to test failure handling.
-
Capacity policies and regional failover.
Observability essentials
-
Metrics for latency, throughput, and errors.
-
Distributed tracing with correlation IDs.
-
Structured logs with PII controls and retention rules.
-
Executive and SRE dashboards plus synthetic checks.
Architecture Patterns That Reduce Regret
For SOA, terminate external calls at a smart gateway to enforce auth, rate limits, and resiliency. Use bulkheads to isolate fragile integrations and caching with domain-appropriate invalidation. The strangler pattern helps peel out change-heavy modules as separate deployables later.
For microservices, favor event choreography with idempotent consumers, apply saga patterns for long-running business transactions, and enforce API standards for errors and versioning. Polyglot persistence is fine when ownership and catalogs are clear.
These patterns reduce coupling, contain failures, and keep teams fast without sacrificing control.
DZ deep dives
How To Choose The Right Architecture
Begin by scoring seven factors from one to five: release frequency, uptime and recovery targets, integration
complexity, DevOps and SRE maturity, budget constraints, data consistency needs, and security scope. Lower totals favor SOA or a modular monolith with clear interfaces. Higher totals favor microservices with strong platform guardrails.
Mixed profiles suggest a blended approach that keeps integration services in an SOA style while product domains evolve as microservices. Revisit boundaries quarterly based on telemetry to consolidate or extract services as needed.
Use contracts and ownership to prevent hidden coupling as you grow.
Helpful DZ comparators
Real-world Scenarios
For an internal enterprise portal with many back-office integrations, SOA delivers standardized contracts and predictable change windows; add caches and circuit breakers for fragile endpoints and extract high-change areas later.
For a consumer application with global traffic and frequent experiments, start with a few microservices around auth, catalog, and checkout, keeping cross-cutting concerns like notifications as shared platform services; rely on canary releases and autoscaling.
For a startup MVP, ship a modular monolith with domain folders and an event spine so extraction is easier when usage and team size demand it. Community perspective often favors starting simple then splitting where it pays off. This staged mindset prevents premature complexity.
Perspective from the community (UGC): modular monolith first, split only where justified.
Implementation Roadmap
A pragmatic roadmap avoids big-bang rewrites and proves the platform early. Begin with inception and guardrails to agree on goals, non-functional targets, and success metrics, then shape domains and data ownership before writing code.
Lay CI/CD, runtime, security, and observability rails so teams can adopt a repeatable “golden path.” Deliver a thin vertical slice that exercises the full path to production with feature flags and SLO-driven dashboards.
Scale to more domains with progressive delivery and chaos drills, then plan data migrations and cutovers carefully. Close the loop with go-live readiness, blameless reviews, and quarterly boundary reviews driven by telemetry. This staged plan fits both SOA and microservices.
Phase 1. Inception and Guardrails
Objectives
Align goals, non-functional requirements, and governance, then publish standards.
Activities
-
Document top five user journeys and target SLOs.
-
Map domains and dependencies.
-
Create short ADRs for runtime, data, deployment, and API style.
-
Publish coding standards, branching, and service templates.
-
Approve privacy and security baselines with identity and secrets policies.
Artifacts
Vision brief, domain map, SLO sheet, initial ADRs, security baseline.
Exit criteria
Scope approved, SLOs signed off, standards published.
Phase 2. Domain and Data Design
Objectives
Align boundaries with business capabilities and reduce coupling.
Activities
-
Run domain discovery to define bounded contexts.
-
Assign data ownership per context and publish a lightweight catalog.
-
Choose integration patterns like APIs, events, or CDC.
-
Define versioned API contracts and error models with testable stubs.
Artifacts
Context map, API specs, event schemas, ownership matrix.
Exit criteria
Interfaces and ownership documented, contracts testable.
Phase 3. Platform Foundations
Objectives
Build CI/CD, runtime, security, and observability rails before scaling teams.
Activities
-
CI/CD with automated tests and environment promotion.
-
Container or runtime templates with health and readiness probes.
-
Observability stack for metrics, logs, traces, alerts, and runbooks.
-
Secrets and config management with rotation and audit.
-
API gateway or service mesh with mutual TLS and rate limiting.
Artifacts
Pipeline templates, IaC modules, dashboard library, runbook skeletons.
Exit criteria
A “golden path” template any new SOA component or service can adopt.

Phase 4. Build the First Thin Slice
Objectives
Deliver a vertical slice that exercises the platform end to end.
Activities
-
Select one high-value user journey.
-
Implement components behind the gateway with automated tests.
-
Wire dashboards for the slice and configure SLO-based alerts.
-
Release with a feature flag and measure latency and error rates.
Artifacts
Working slice in staging and production, dashboards, SLO reports.
Exit criteria
Production learning captured; issues triaged with owners and timelines.
Phase 5. Scale Delivery and Hardening
Objectives
Add domains while maintaining reliability and security.
Activities
-
Onboard two to four domains with service templates and seeded dashboards.
-
Introduce canary and blue-green deployments with automated rollback.
-
Run chaos experiments on non-critical flows.
-
Enforce least privilege, dependency scanning, signed images, and SBOMs.
Artifacts
Service catalog, security checklist, chaos results.
Exit criteria
Consistent releases, error budget compliance, clear incident process.
Phase 6. Data and Migration Strategy
Objectives
Manage data quality and legacy cutover without risk.
Activities
-
Choose storage per domain; define retention, backups, and recovery tests.
-
For microservices, use CDC for replication and an outbox pattern for reliable events.
-
For SOA, design caching and bulkheads and plan staged cutovers.
-
Validate migrations with shadow traffic or replay tests.
Artifacts
Migration runbook, rollback plan, verification scripts.
Exit criteria
Successful dry runs, signed-off go-live window, rollback rehearsed.
Phase 7. Go-Live, Measure, Improve
Objectives
Launch safely and iterate based on telemetry and feedback.
Activities
-
Run a go-live readiness review using the checklist below.
-
Launch with progressive delivery and monitor health.
-
Hold a blameless review; update ADRs and templates.
-
Reassess boundaries quarterly based on telemetry.
Artifacts
Launch notes, incident timeline, updated ADRs, improvement backlog.
Exit criteria
SLO adherence met for at least one full release cycle.
Go-Live Readiness Checklist
-
SLOs defined for top journeys and alerts tested.
-
Rollback and data restore rehearsed.
-
Rate limits and circuit breakers validated.
-
Security scans clean, secrets rotated, least-privilege service accounts.
-
Dashboards published for product, engineering, and operations.
Example 90-Day Plan
| Week | Focus | Outcomes |
|---|---|---|
| 1 to 2 | Phase 0 guardrails, SLOs, ADRs | Scope agreed, standards published |
| 3 to 4 | Domain design and contracts | Context map, API specs, event schemas |
| 5 to 6 | Platform foundations | CI/CD live, observability ready |
| 7 to 8 | First thin slice | Production telemetry and feedback |
| 9 to 10 | Additional domains | Two domains shipped with canary |
| 11 to 12 | Hardening and migration prep | Chaos drills, security checks, cutover plan |
RACI for a Typical Program
| Activity | Product | Tech Lead | Platform/SRE | Security | QA |
|---|---|---|---|---|---|
| SLO definition | A | C | C | I | C |
| Domain boundaries | C | A | I | I | I |
| Pipeline templates | I | C | A | C | I |
| Security baseline | I | C | C | A | I |
| Release and rollback | C | A | A | C | C |
CI/CD Quality Gates
-
Unit, integration, and contract tests must pass; consider a mutation score threshold.
-
Static analysis and dependency scanning with policy gates.
-
Performance budgets enforced on key endpoints.
-
Release notes auto-generated with ADR references.
Observability Stack Quick Table
| Layer | What to capture | Why it matters |
|---|---|---|
| Metrics | Latency, throughput, error rate | Track SLOs and autoscaling |
| Traces | Cross-service spans with IDs | Pinpoint slow or failing hops |
| Logs | Structured JSON with context | Debug incidents and audits |
| Synthetics | Journey checks every few minutes | Catch issues before users feel them |
Security Controls to Bake In
-
Central identity with short-lived tokens and mutual TLS.
-
Secrets manager with rotation; no secrets in code or images.
-
Image signing, SBOMs, and admission policies at deploy time.
-
Data encryption at rest and in transit with clear key custody.
Migration Patterns
-
Strangler fig for legacy replacement.
-
Outbox and CDC for reliable events.
-
Shadow reads before cutover.
-
Time-boxed dual writes with consistency checks only when required.
KPIs and Review Cadence
-
Deployment frequency, change failure rate, and mean time to recovery.
-
Cost per transaction, error budget burn rate, uptime per SLO.
-
Quarterly boundary review to consolidate or extract services based on telemetry.
Share your top two user journeys, current pain points, and non-functional targets like availability or regional latency. I will return a tailored phase plan, proposed domain boundaries, and a 90-day execution map that fits your team and budget.
For platform ideas, see Building Microservices in Java and Web App Development Services.
14) FAQs
Q1. Is microservices always more scalable than SOA?
Not automatically. Microservices enable granular scaling, but only if boundaries are clean and the platform is mature. Poor boundaries can create a distributed monolith that scales worse than a well-structured SOA or modular monolith. AWS and IBM both emphasize scope and design as the deciding factors.
Q2. Can I combine SOA and microservices?
Yes. Many enterprises run SOA at the integration layer and microservices for change-heavy domains, using contracts and clear ownership to avoid bottlenecks. This blended approach is common in cloud environments.
Q3. What are the biggest adoption challenges today?
Cloud-native surveys highlight complexity, documentation gaps, and multi-cloud observability as top pain points. Platform engineering and stronger standards address these risks.
Q4. How expensive is downtime if we get this wrong?
Siemens estimates about 11 percent of revenues lost to unplanned downtime among the largest firms, and multiple reports place many high-impact outages around two million dollars per hour. Invest in observability and progressive delivery to cut both frequency and impact.
Conclusion
Want a pragmatic build sheet for SOA, microservices, or a blended path that your team can start this sprint? Share your repo count, pipeline status, and monitoring tools. I will shape a golden path template and a go-live checklist you can adopt quickly. If you need a staffed team, explore Hire Experienced Developers.

Author Profile: Mahipal Nehra is the Digital Marketing Manager at Decipher Zone Technologies, specializing in SEO, content strategy, and tech-driven marketing for software development and digital transformation.
Follow us on LinkedIn or explore more insights at Decipher Zone.