

Apache Beam Using Java. A data pipeline helps developers move data from source to destination while optimizing and transforming data to be analyzed and used for developing business insights. And with modern data pipelines, the transformation and optimization of continuous data loads become automated. Speaking about data pipelines, we will cover an open-source unified model for parallel-processing data- Apache Beam for developers who want to use its SDK for creating data pipelines. It is an Apache Software Foundation project that makes batch processing and streaming data easier.
So let’s get started.
What is Apache Beam?
Apache Beam is a unified model that defines batch and stream data parallel-processing pipelines. It simplifies the large-processing pipelines’ mechanics. Beam provides a software development kit (SDK) for programming languages like Java, Python, and Go that helps define and develop data processing pipelines and runners to execute them.
Read: Apache Kafka
The initial version of Apache Beam was published in June 2016, while its stable version was published in October 2018. Apache Beam also offers a portable layer for programming while its runners translate data processing pipelines into the API compatible with the user’s choice backend. Some of the supporting distributed processing runners are:
Read: Principles of Web API Design
-
Google Cloud Dataflow
-
Apache Apex
-
Apache Flink
-
Apache Samza
-
Apache Spark
-
Hazelcast Jet
-
Apache Gearpump
-
Twister2
-
Direct Runner
The Basic Apache Beam Model
Before starting to work with Apache Beam, it is necessary to understand the basic yet essential concepts of the beam model.
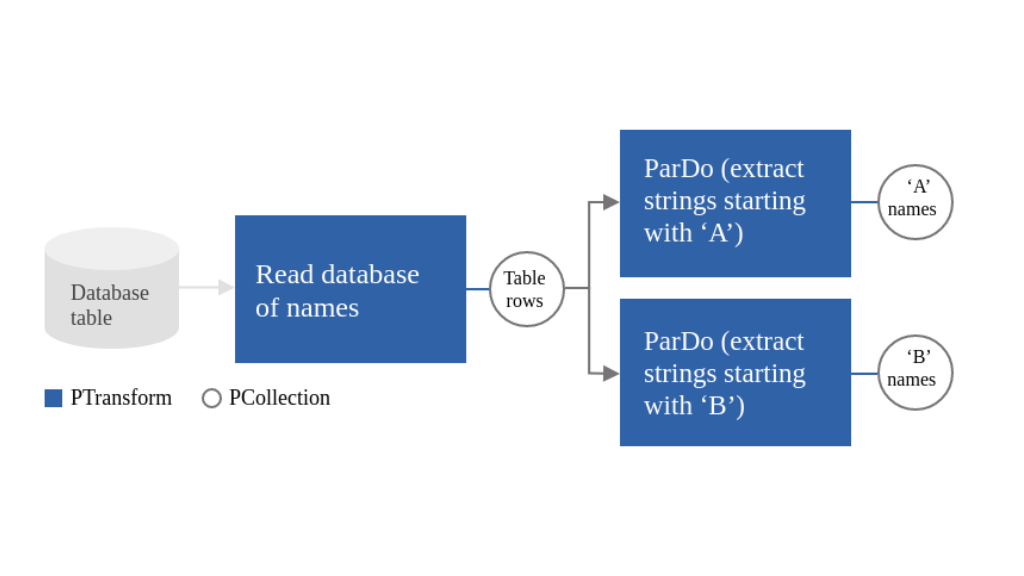
They are as follows:
Read; Apache Pinot Architecture
-
Pipeline - The Apache Beam pipeline is a graph of all the computation and data in the data processing pipeline. It represents transformations of the chosen data processing operations. The Beam pipeline encapsulates the entire data processing task. The processing pipeline consists of input data reading, transforming, and writing outputs, as shown in the below figure.
-
PCollection - A PCollection is a distributed data set on which the pipeline operates. The data set can either come from a fixed source (bounded) or a continuously updating source (unbounded). A PCollection can only work with one pipeline instead of being shared with multiple processing pipelines. While the pipeline processes the PCollection, its elements can be kept in the runner.
-
PTransform - A PTransform (or transform) represents an operation on data. PTransform takes one or more object input from PCollection, performs processing functions on the element, and produces zero or more object PCollection as output.
-
Aggregation - In aggregation, the multiple input elements computing value is defined. The primary aggregation computational pattern is to group elements with a standard window and key and then combine them through commutative and associative operations.
-
User-defined function (UDF) - With a few Beam operations, developers can run user-defined code to configure transform. Beam contains different user-defined codes, like WindowFn (place elements in windows and merge them), DoFn (process per-element function), CombineFn (does commutative & associative aggregations), ViewFn (materialized PCollection adoption to an interface), Coder (encodes user information), and WindowMappingFn (maps elements’ windows to each other and defines the result window timeline).
-
Schema - A schema is a PCollection definition that is language-independent. It defines elements of a particular PCollection as name fields in an ordered list. Here each field has a type, name, and user options (often).
-
SDK - A software development kit (SDK) is a library that is programming language-specific. It allows developers to build, construct, transform their pipelines and then submit those pipelines on a runner.
-
Runner - To run an Apache Beam pipeline on a specific platform, we use runners. These runners are either adaptors or translators of parallel big data processing systems like Apache Spark, Flink, etc. The Direct runner available on Apache Beam runs pipelines to test, validate, and debug locally to determine if the pipeline works according to Apache Beam closely or not.
-
Window - To subdivide a PCollection into timestamped elements windows, we use the windowing function. It enables operation grouping on unbounded collections by dividing collections into finite collections’ windows. The window function informs the runner about assigning elements to multiple (1 or more) windows and combining those windows into grouped elements. Some of the windowing functions that Apache Beam offers are Fixed Time Windows, Per-Session Windows, Sliding Time Windows, Calendar-based Windows, and Single Global Windows.
-
Watermark: Watermarks are estimates of when all of the data within a certain window will arrive. We need watermarks because a pipeline cannot always guarantee that data will arrive at predictable intervals.
-
Trigger - At the time of grouping data into windows, Apache Beam’s trigger function is used to send the aggregate of each window's result. Some of the pre-built triggers that Beam has are event-driven triggers, data-driven triggers, processing time triggers, and composite triggers.
-
State and timers - These primitives provide a lower-level way to aggregate input collections that expand over time, using callbacks that provide complete control. A few state types supported by Apache Beam are ValueState, Combing state, MapState, SetState, BagState, and OrderedListState. And some of the timers that are available in Apache Beam are Processing-time Timers, Event-time Timers, and Dynamic Timer Tags.
-
Splittable DoFn - Splittable DoFns enable pipeline developers to process elements in a non-monolithic way. With Splittable DoFn, it becomes easier to develop modular, complex input/output connectors. It also provides checkpointing that allows you to split up the remaining work into multiple threads, giving you more parallel processing power.
Apache Beam Program Working
The basic Apache Beam-driven program works in the following ways:
-
A pipeline object is created and its execution options consisting of runners are defined.
-
Now you need to create a PCollection for data in the pipeline by using IOs to read external storage system data or create a transform from in-memory data to create a PCollection data.
-
Then each PCollection should be applied with PTransforms that can change, group, filter, analyze, or process the PCollection elements. It will also create a new PCollection output without the need to modify PCollection inputs.
A basic pipeline will apply succeeding transforms to every new PCollection output till the completion of processing. Keep in mind that PCollections are sort of variables and PTranforms are functions that are implemented on these variables, so the pipeline shape can be a complex processing graph instead of a single straight line.
Read: Graph Databases
-
To write the final, transformed PCollection to any external source you can use IOs.
-
Lastly, you can use a designated runner to run the pipeline.
At the time of running the Apache Beam program, the designated runner creates a graph that represents the pipeline workflow according to the PCollection objects that were built and transformed in the pipeline. Using the appropriate processing back-end, the graph is executed.
Why Apache Beam?
The primary reason why one uses Apache Beam is that it combines batch and stream processing of data which makes it easier to change batch into stream process and vice versa. It also increases the flexibility of the data processing.
Read: Addressing the Microservices States, Scalability, and Streams
But that’s not all, Apache Beam has other advantages as well, they are as follows:
-
Unified: It is a single, simplified programming model for both streaming and batch processing for each application and data team member.
-
Open Source: Apache Beam also comes with open community development support to help an application meet certain requirements according to your requirements.
-
Extensible: Tools such as Apache Hop and TensorFlow can be extended by Apache Beam.
-
Portable: Apache Beam can execute its data pipelines on different run-time environments that help in avoiding lock-in and provides flexibility.
Dependencies in Java
Before implementing the workflow graph in Java, developers should add Apache Beam’s dependencies to the project as
Read: Microservices in Java
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>${beam.version}</version>
</dependency>
The pipeline runners in Apache Beam depend on the distributed backend processing, so adding DirectRunner is also important as a runtime dependency.
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>${beam.version}</version>
<scope>runtime</scope>
</dependency>
However, DirectRunners does not need any external setup like other runners, making it a good starter option.
Creating Apache Beam Pipeline in Java
You need to create an Apache Beam SDK instance of class Pipeline and then configure its options.
|
You can use the pipeline options to configure pipeline aspects like the runner that will run the pipeline.
To configure the pipeline and setting fields, you can create a PipelineOptions as follows:
|
Now to create custom options to the PipelineOptions you will need to define the interface with setter and getter methods as:
|
|
To set the default value and description using annotations, write:
|
Now you will have to register the PipelineOptionsFactory to pass the PipelineOptions Object interface as:
|
This will allow you to accept –output=value and –input=value as CLI arguments.
How To Create Apache Beam PCollections in Java
Apache Beam Using Java. You can create Apache Beam PCollection either by using Source API from Beam to read external source data or create an in-memory data PCollection class in the program.
Here we will discuss creating PCollection from external sources.
Read: Best Practices for Unit Testing in Java
So, a developer can use a Beam-provided I/O adapter to read from an external source. Keep in mind that each data source adapter will have a Read transform so you must apply that transform Pipeline Object as
|
Applying PTransform
If a developer wants to invoke transform then PCollection input must be applied to it as:
|
One can use both chains transforms as Beam uses a generic apply PCollection method.
Key Takeaways
Although there is much more to Apache than mentioned in this blog. That was it for Apache Beam from our side and we hope it was helpful for you. You can read the Apache Beam documentation that will serve as a programming guide for your project.
However, if you are a business owner who wants to develop a web application with Apache Beam, then hire experienced developers from companies like Decipher Zone Technologies now!