

Steps for Building a Data Warehouse from Scratch. In today’s world, where advancing technology drives organizations’ success, enterprises rely on adequate data storage, collection, and integration from multiple sources to gain valuable insights.
With more corporations turning to cloud-based technologies for convenience data collection and analysis, data warehouse demand has also increased.
But before investing in data warehousing, it is essential to understand what it is and why it is significant. To help you, we will provide a data warehouse overview, and explore its structure, key technologies, use cases, and the approaches and steps to build data warehouses.
With that said, let's begin!
An Overview of Building a Data Warehouse from Scratch
Data warehouse refers to the system used by businesses to analyze and report semi-structured and structured data from disparate sources.
These sources can include data from marketing automation, customer relationship management, relational databases, point-of-sales transactions, websites, native apps, and more.
Read: Warehouse Management Software System
It is a central information repository that helps make analyzed and informed decisions. In short, data warehouses are like data management systems that support business intelligence activities like analysis.
Read: Metaverse Use Cases and Benefits
In the data warehouse, data is pulled periodically from different internal and external sources to be analyzed and used by decision-makers of an organization.
Why to Build a Data Warehouse from Scratch?
Although collecting and analyzing entire structured and unstructured data in one place is one of the most significant advantages a business can achieve from data warehouse development, there are other benefits of having a data warehouse that we have listed below.
1. Better Decision-Making:
Data is essential for making informed business decisions. However, without proper organization, making sense of the massive amount of data becomes difficult. Using a data warehouse enables organizations to store and organize data in a structured way for conducting easy data analysis and deriving insights.
2. Improved Data Quality:
Data quality is crucial for organizations. Poor-quality data can lead to wrong decisions, missed opportunities, and inaccurate reporting. So, organizations can use a data warehouse to ensure data consistency, accuracy, and completeness by integrating data from different sources and eliminating duplicates.
3. Faster Query and Reporting:
Querying data from different sources can be time-consuming and complex. A data warehouse allows organizations to retrieve data quickly and easily, reducing the time required for data analysis and reporting.
4. Enhanced Data Security:
Needless to say, data security is a critical concern for organizations. Data warehouses provide a centralized location to store and manage data which makes implementing security measures and ensuring data privacy easier.
5. Scalability:
As organizations grow, their data requirements also increase. And to scale up the data storage and processing capabilities, a company can use a data warehouse that can comply with their evolving needs.
Essential Structure of Building a Data Warehouse from Scratch
To build a data warehousefrom scratch, it is essential to include five basic structures, i.e, Operational Software, Data Sources, ETL Processes, Data Storage, and Metadata.
1. Data Sources
These are the systems from where the data is pulled to the data warehouse. Data sources can include transactional databases, flat files, spreadsheets, and more. Besides, ETL processes are used to connect these data sources to the data warehouse for analysis.
This brings our attention to the -
2. ETL Processes
ETL (extract, transform, load) processes are responsible for extracting data from the data sources, transforming it into a format suitable for analysis, and loading it into the data warehouse. ETL processes can be complex and time-consuming, but they are critical to ensuring the quality and consistency of the data in the data warehouse.
3. Data Storage
It is where the data warehouse stores the data. Data storage can be a relational database, a multidimensional database, or a hybrid of the two. However, the choice of data storage method depends on the specific needs of the organization.
4. Metadata
Metadata is data about the data stored in the data warehouse. It provides context and meaning to the data and is critical to ensuring that the data is properly understood and used by decision-makers.
5. Operational Software
It consists of the operational part of the data warehouse that can be divided into centralization and visualization software. Where centralization software collects and maintains data, and visualization software represents the analyzed data in visual form.
Approaches to Build Data Warehouse from Scratch
To build a data warehouse from scratch, you can follow either of the two most common approaches:
Inmon’s Approach
Inmon recommends following the top-down approach to build data warehouses. According to Inmon’s philosophy, you need to start with creating a big centralized data warehouse for an enterprise where data from different sources (transaction systems) are reduced into an integrated, non-volatile, subject-oriented, and time-variant data collection to support decision-making.
Introduced by Bill Inmon, this approach identifies the core subject entities and areas of the enterprise such as vendors, customers, products, etc. Inmon is used to create detailed logical models for each primary entity. A physical model is then developed based on the detail and model.
Use the ETL process to fetch data from disparate sources, then transform and load it into a normalized data model. To avoid redundancy data is kept in the 3rd normal form.
Needless to say, for a data warehouse built using Inmon’s approach normalized data models are the core. The Inmon approach thus helps in clearly identifying business needs and minimizing any irregularities in data updates.
Flexibility, fewer errors, having a single truth of source, and completeness are some of the advantages of using Inmon’s approach.
While some of the disadvantages of Inmon’s approach include higher set-up and maintenance costs, more ETL requirements, and the need for higher skills.
Kimball’s Approach:
Introduced by Ralph Kimball, Kimball’s approach recommends following a bottom-up approach. In contrast to Inmon’s approach, Kimball suggests starting with mission-critical data marts that can help with the analytics requirements of a department.
These data marts are then integrated for data consistency through the information bus.
Kimball’s approach is used to design a data warehouse by recognizing business processes and requirements that need to be fulfilled. All the data sources throughout the enterprise are then analyzed and documented.
Then an ETL (extract, transform, and load) - a three-phase process that combines data from disparate sources into a single output data container is used to load data into a denormalized data model. Finally, the data model is built as a snowflake or star schema surrounded by dimensional tables.
Some major advantages of using Kimball’s approach are simplicity, speed, easy understanding, relevancy, and the requirement of fewer engineers.
Data redundancy, no single truth source, less flexibility, and incomplete reporting are some of the disadvantages that Kimball’s approach comes with.
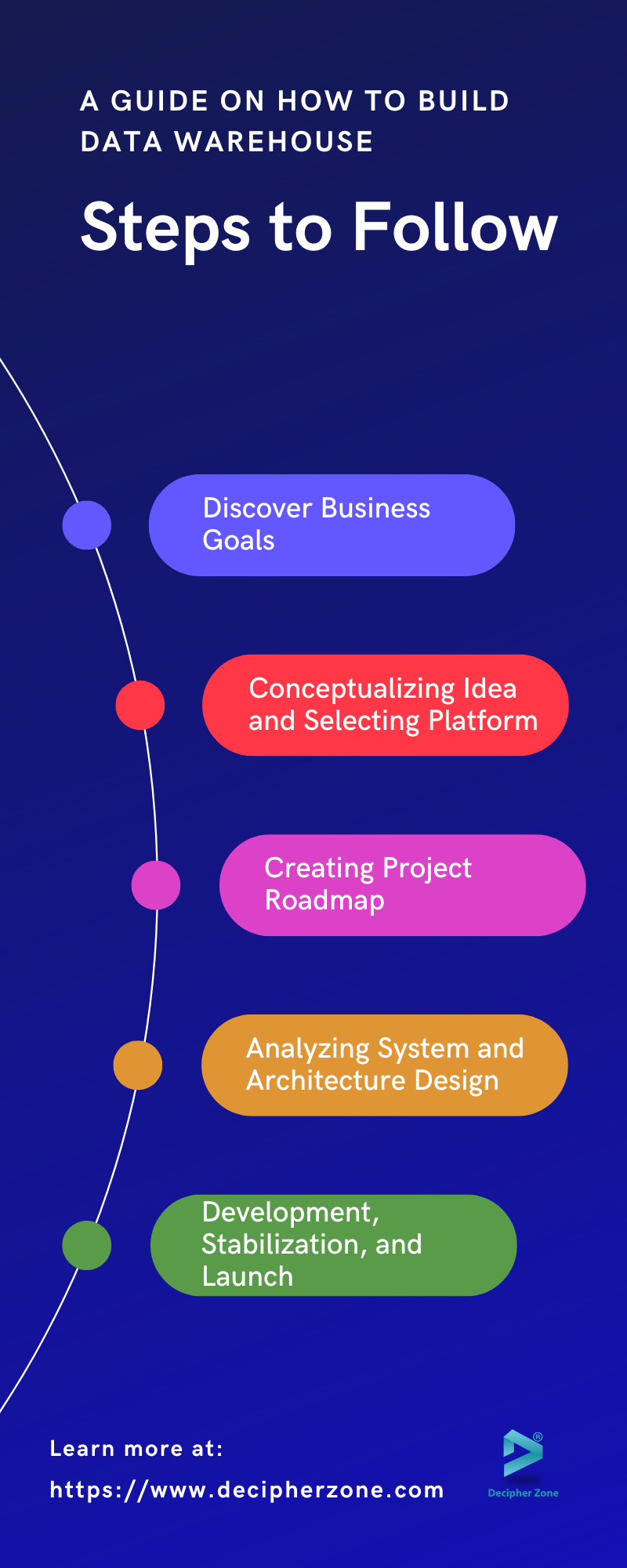
6 Steps to Building Data Warehouse from Scratch
6 steps you need to follow to build the data warehouse from scratch.
1. Discover Business Goals
Before investing in data warehouse development, you should ask yourself: “do we need a data warehouse?”.
It is more likely that you will have fragments of your previous data warehouse if you've been in the market for a long time. Does the business require the development of a new data warehouse?
If the answer is yes, the first step is to discover the business’s tactical and strategic objectives to be achieved using data warehousing. The core requirements can include generating more revenue, improving reporting, and mitigating regulatory risks.
Read: Types of Software Architecture Patterns
To discover the business goal you can review the current tech architecture, used applications, etc., then conduct initial data analysis to outline the data warehouse scope and system requirements.
2. Conceptualizing Idea and Selecting Platform
The next steps involve defining required features, choosing the optimal deployment option (on-premise, cloud-based, and hybrid), selecting the ideal architectural design (Centralized, Data Mart Bus, Independent Data Mart, Hub-and-Spoke, and Federated).
And opting for data warehouse technologies (Amazon Redshift, Snowflake, Microsoft Azure, SQL Server, Google BigQuery, Azure Synapse Analytics, and Oracle Autonomous Data Warehouse) by taking the number of data sources, data volume, data flow, and data security into account.
3. Creating Project Roadmap
Once the conceptualization is completed, you need to create the roadmap to build the data warehouse. It starts with defining the project scope, timeline, budget planning, etc.
Then move ahead with arranging design, development, and testing tasks. In case things went south, you also need to develop a plan for risk management.
4. Analyzing System and Architecture Design
Now comes the most crucial task: analyzing each data source, designing and developing policies for data cleansing, creating data models, identifying data objects as entities and the relationship between these entities, mapping data objects, and designing ETL/ELT processes to control data integration and flow.
5. Development and Stabilization
Next is the customization and development of the data warehouse. To accomplish this, you need to configure data security, implement security policies, develop ELT/ETL pipelines, and ETL/ELT as well as performance testing.
6. Launch and Maintenance
Last but not least, once the data warehouse is developed and you have launched it. You need to conduct data quality checks, introduce it to the new business users, have A/B testing, user training sessions, and keep the data warehouse maintained.
You also need to develop additional ETL/ELT processes to export data from your warehouse to enable sharing, for example, export query results from BigQuery to a spreadsheet or workbook.
Cost for Building a Data Warehouse from Scratch
Data warehouse development from scratch can cost anywhere from $50,000 to $300 million. The development cost highly depends on the number of data sources, disparate sources, data source complexity, data volume, data security requirements, data flow, entities, and performance requirements.
Conclusion
Data warehouses can be used for strategic decision-making, budgeting and financial planning, tactical decision-making, performance management, IoT, Telematics, Digital Twins, SaaS, XaaS, online services, and operational data warehousing.
Needless to say, data warehousing can be highly beneficial for a business if built correctly. If you want to build a data warehouse for your business, you will require project manager, business analyst, data warehouse system analyst, solution architect, data engineer, QA engineer, and DevOps engineer.
But instead of hiring an in-house development team that can be quite expensive, you can outsource developers from Decipher Zone Technologies that have an experienced team of developers with experience in data warehouse development at a pocket-friendly price.