

What is Data Pipeline Architecture? With business digitization, an organization gathers data from on-premise solutions, databases, SaaS applications, and other external data sources leading to mass data production.
Behind every smart-designed machine learning model, business insights, and interactive dashboard is data. But these data are not raw. The data we were referring to is collected from different sources and then processed and combined to deliver value. However, gaining value from these large data sets requires analysis.
Read: Top SaaS Management Tools
Once coined by Clive Humby in 2006, “Data is the new oil” has proven true with almost all the industry being dependent on data. Like oil, the real potential of data is created after it has been refined and provided to the customer. Moreover, it also requires a competent pipeline to deliver data which brings us to our topic “Data Pipeline”.
Read: Popular Database For Web App Development
So what is data pipeline, and what are its features, benefits, and types? Which components and architecture does it use to function properly?
This blog will help you find out!
What is a Data Pipeline?
A data pipeline is a set of processes and actions that are used to move and transform data collected from different sources like NoSQL or SQL databases, APIs, XML files, servers, SaaS platforms, etc. to a destination (data store) like a data warehouse to drive value by analyzing. Data pipelines are the foundation of reporting, analytics, as well as machine learning capabilities.
Read: Principles of Web API Design
With data pipelines, you can automate different data operations like extraction, validation, transformation, and combination for further analysis and visualization. One thing to remember about data pipelines is that the size, structure, and state of the source data can make these pipelines complex.
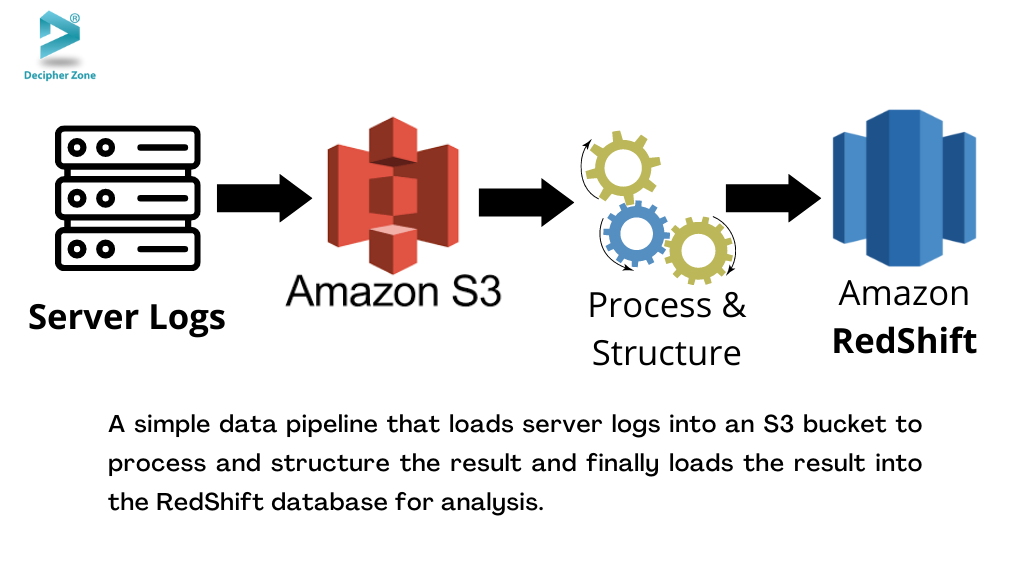 As shown in the image above, in the simplest data pipeline, data is only extracted from one source and then loaded into a destination like the Amazon RedShift database. However, the steps that are involved in data pipelines working include data extraction, validation, preprocessing, and even running or training a machine learning model before it loads/delivers the final results to the set destination.
As shown in the image above, in the simplest data pipeline, data is only extracted from one source and then loaded into a destination like the Amazon RedShift database. However, the steps that are involved in data pipelines working include data extraction, validation, preprocessing, and even running or training a machine learning model before it loads/delivers the final results to the set destination.
Read: What is a Graph Database
Another interesting thing to note when working with data pipelines is that they can contain multiple programming languages and systems handled by the data engineers’ team to maintain multiple dependencies in different pipelines.
Some of the popularly used data pipeline tools are AWS Data Pipeline, Hevo, Integrate.io, Apache Airflow, and Fivetran.
Types of Data Pipeline
Let’s take a step ahead and find out the types of data pipelines.
Data pipelines are of two main types, namely, batch processing and streaming (real-time). What does each of these terms mean? Let us help you understand.
Batch processing
Batch processing used to be a critical step in developing reliable data infrastructure. It is a process in which data “batches” are loaded into a repository at intervals, often at quiet business hours. This was done to avoid any impact on workload.
Read : Microservices in Java
It is majorly used when a business wants to move large data volumes at regular intervals. It is the best data pipeline when you don’t need data analysis immediately. Batch processing is more linked to the ETL (extract, transform, and load) process for data integration.
Batch processes form sequential workflow commands where output becomes the input of the next command. These commands can trigger filtering, data ingestions, or aggregation until the data is completely transformed and loaded into a data repository.
Streaming data
Stream processing is a relatively new approach in comparison to batch processing. Streaming data is mainly used when a company wants data to be continuously updated. It takes advantage of cloud processing power to transform data in real-time. Stream processors get data as created in the source, then process and distribute it to the destination in continuous flow.
Read: Process of Product Development
As stream processors execute data events just after the occurrence, they tend to have lower latency than batch processing. However, it is not as reliable as batch processing because messages get dropped unintentionally or spend a long time in the queue while streaming data. However, this problem can be solved with message brokers through acknowledgments where a user can confirm message processing to the broker to terminate it from the cue.
Data Pipeline Components
After defining what a data pipeline is and what its types are, we will move on to some of the basic components of a data pipeline that are essential to know about if you are planning to work with it.
Read: IoT on Web Development
-
Origin: In a data pipeline, the origin is the point where data is entered. An origin can be an application (transaction processing system, IoT device, or API) or a storage system (data lake or data warehouse) of the reporting and analytical data environment.
-
Destination: A destination is where data is transferred. Data can be sourced for data analytics and visualization tools or transferred to a data lake or a data warehouse, depending on the use case.
-
Dataflow: In the data flow, data moves from one place to another, including the changes along the way and the data stores it passes through.
-
Storage: Storage is the system where different stages of data are stored while it passes through the data pipeline. The storage options for data can vary because of different factors like frequency, data volume, queries, and much more.
-
Processing: Data processing consists of steps that are used for ingesting data from different sources to store, transform and deliver it to the final destination. Although it is a bit related to data flow, the core aim of processing is the way to implement the movements involved.
-
Workflow: Workflow represents the process sequence as well as its dependencies in the data pipeline.
-
Monitoring: The purpose behind data monitoring is to validate and check if the data pipeline’s processes are working properly. Monitoring includes checking and managing regularly increasing data load, its accuracy, and consistency while making sure that no data is lost along the way;
Architecture for Data Pipeline
What is Data Pipeline Architecture? The three major steps in the data pipeline architecture are data ingestion, transformation, and storage.
Read: Data-Oriented Programming in Java
1. Data ingestion:
A variety of data sources are used to collect data (structured and unstructured data). Streaming data sources are often called producers, publishers, or senders. It is always better to practice storing raw data in the cloud data warehouse before extracting and processing it.
Methods like data composability also help businesses to update any previous data records to make adjustments in data processing jobs.
2. Data Transformation:
This step involves processing data into the format required by the destination data repository through a series of jobs. By automating repetitive workstreams, such as business reporting, these jobs ensure that data is consistently cleansed and transformed. For instance, at the time of the data transformation stage, key fields may be extracted from nested JSON streams, such as a data stream in nested JSON format.
3. Data Storage:
After the transformed data has been stored, it is made available to a variety of stakeholders within a data repository. The transformed data are typically referred to as consumers, subscribers, or recipients within streaming data.
Data Pipeline vs ETL Pipeline
Some of the newbies in the data engineering field get confused when it comes to data pipelines and ETL pipelines. And if you are one of those newbies, then we will help you understand the difference between these two.
Read: data Streaming Platform
An ETL pipeline refers to a set of scheduled processes. As part of the ETL process, data is extracted from one system, rudimentary transformations are performed on the data, and the data is loaded into a repository like a database, a warehouse, or a lake.
On the other hand, a data pipeline is a set of activities that incorporates advanced data operational and business intelligence to work on advanced data sourcing, loading, and transforming. A data pipeline can work in one of the three ways:
-
It can run on a scheduled basis,
-
Triggered by a set of rules and conditions, or
-
In real-time by streaming.
Takeaway
Needless to say, data pipelines are a core part of modern data handling and strategizing. Data pipelines help you to connect data between different organizations along with stakeholders requiring it. With effective data movements, data engineers can support in-depth data analysis to gain useful insights for better decision-making.
With numerous design architectures and tools for developing the pipeline, it becomes easier to achieve better analysis. But before starting to work with data pipelines, one important thing is to realize how much data can help your organization to leverage its business.
If you are a business owner who wants to build an app based on Data Pipeline, then get in touch with our experienced developers who will help you in developing high-end and powerful end projects.
So that was it in the blog, we hope it helped you understand the basics of data pipelines, their types, components, architecture, and the difference between data and ETL pipelines.